Google:TensorFlow怎样表示非数值特征类型
时间:2021-01-23 | 标签: Google | 作者:Q8 | 来源:Google开发者网络
小提示:您能找到这篇{Google:TensorFlow怎样表示非数值特征类型}绝对不是偶然,我们能帮您找到潜在客户,解决您的困扰。如果您对本页介绍的Google:TensorFlow怎样表示非数值特征类型内容感兴趣,有相关需求意向欢迎拨打我们的服务热线,或留言咨询,我们将第一时间联系您! |
我们将在这篇文章中介绍特征列 (Feature Column) - 一种说明估算器进行训练和推理所需特征的数据结构。正如您将在下文看到的一样,特征列的信息非常丰富,它让您可以表示各种数据。
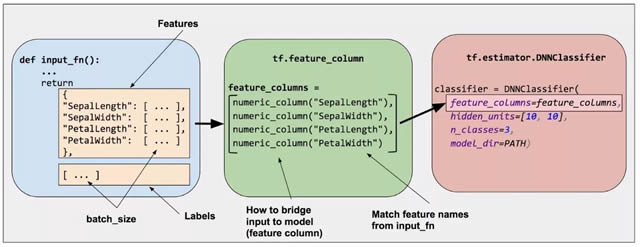
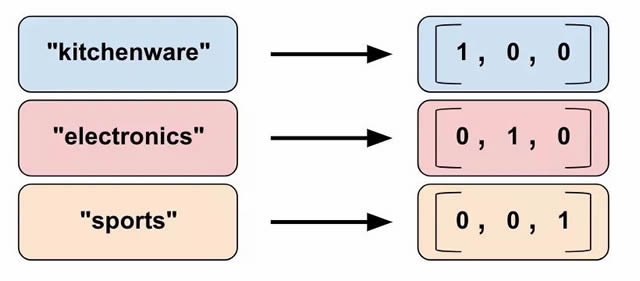
怎样才能表示非数值特征类型呢?这正是我们这篇文章要讨论的内容。 深度神经网络的输入 先来问个问题:我们实际上是将哪种数据输入深度神经网络?当然,答案是数字(例如 tf.float32)。毕竟,神经网络中的每一个神经元都会对权重和输入数据执行乘法和加法运算。不过,现实世界中的输入数据经常包含非数值(分公关危机英剧在哪里看类)数据。例如,假设存在一个包含以下三个非数字值的 product_class 特征: a.kitchenware (厨房用品) b.electronics (电子产品) c.sports (体育用品) 机器学习模型一般以简单矢量表示分类值,其中,1 表示某个值存在,0 表示某个值不存在。例如,当 product_class 设为 sports 时,机器学习模型通常会以 [0, 0, 1] 表示 product_class,含义如下所示: a.0:kitchenware 不存在 b.0:electronics 不存在 c.1:sports 存在 所以,尽管原始数据可以是数值或分类数据,机器学习模型会以数字或由数字组成的矢量表示所有特征。 特征列介绍 如图 2 中所示,您可以通过估算器(鸢尾花为 DNNClassifier)的 feature_columns 参数指定模型的输入。特征列将输入数据(由 input_fn 返回)与您的模型联系起来。
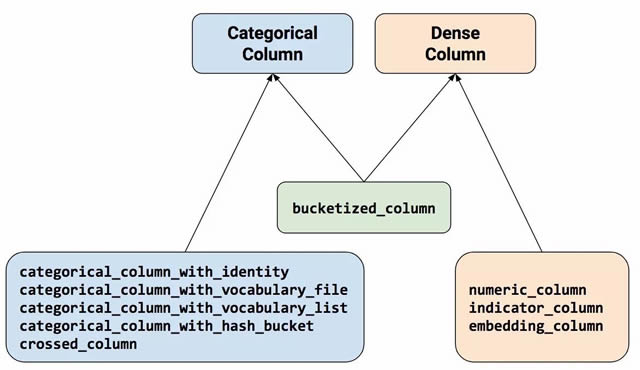
图 2.特征列将原始数据与您的模型需要的数据联系起来 要以特征列表示特征,请调用 tf.feature_column 软件包的函数。这篇文章将介绍此软件包中的九个函数。如图 3 所示,所有九个函数都会返回一个 Categorical-Column 或 Dense-Column 对象,但 bucketized_column 除外,它继承自这两个类别:
图 3.特征列函数可以归入两个主要类别和一个混合类别 我们来详细看一下这些函数。 数值列 鸢尾花分类器为所有输入特征调用了 tf.numeric_column():SepalLength、SepalWidth、PetalLength、PetalWidth。尽管 tf.numeric_column() 提供了可选参数,调用不含任何参数的函数仍是指定具有默认数据类型 (tf.float32) 的数字值作为模型输入的一种极简单方式。例如:
使用 dtype 参数可以指定非默认数值数据类型。例如:
默认情况下,一个数值列可以创建一个值(标量)。使用 shape 参数可以指定另一个形状。例如:
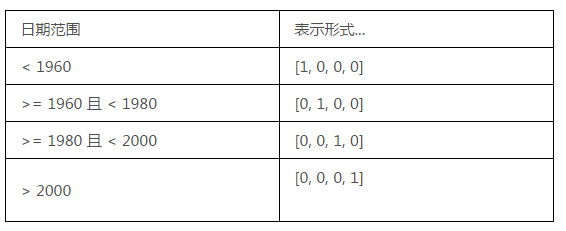
存储分区化列 (Bucketized Column) 通常,您不希望将数字直接提供给模型,而是根据数值范围将它的值拆分成不同的类别。为此,请创建一个存储分区化列。例如,假设存在表示房子建造年份的原始数据。我们可以将年份拆分成以下四个存储分区,而不是以标量数值列表示年份:
图 4.将年份数据分成四个存储分区
模型将通过以下方式表示存储分区:
既然数字对模型来说是一种非常有效的输入,为什么还要将它拆分成这样的分类值呢?请注意,分类可以将一个输入数字拆分成一个四元素矢量。因此,模型现在可以学习 四个单独的权重 ,而不是仅仅学习一个。与一个权重相比,四个权重可以创建信息更丰富的模型。更重要的是,由于只有一个元素置位 (1),其他三个元素清零 (0),存储分区化可以让模型清楚地区分不同的年份类别。如果我们仅使用一个数字(年份)作为输入,模型无法区分类别。所以,存储分区化可以为模型提供可以用来学习的其他重要信息。 下面的代码演示了如何创建存储分区化特征:
请注意以下事项: a.在创建存储分区化列之前,我们先创建了一个数值列来表示原始年份。 b.我们将数值列作为第一个参数传递到 tf.feature_column.bucketized_column() 中。 c.指定一个 三元素边界(boundaries)矢量可以创建一个 四元素存储分区化矢量。 分类标识列 (Categorical Identity Column) 分类标识列是一种特殊形式的存储分区化列。在传统的存储分区化列中,每个存储分区表示一个 范围 的值(例如,从 1960 到 1979)。在分类标识列中,每个存储分区表示 一个唯一整数。例如,我们假设您想要表示整数范围 [0, 4)。(即,您希望表示整数 0、1、2 或 3。)在这种情况下,分类标识映射如下所示:
图 5.分类标识列映射。请注意,这是一种独热编码,而不是二进制数字编码。 那么,您为什么想要以分类标识列表示值呢?使用存储分区化列,模型可以在分类标识列中为每个类别学习单独的权重。例如,与使用一个字符串表示 product_class 相反,我们使用一个唯一整数值表示每个类别。即: a.0="kitchenware" b.1="electronics" c.2="sport" 调用 tf.feature_column.categorical_column_with_identity() 来实现一个分类标识列。例如:
分类词汇列 (Categorical Vocabulary Column) 我们无法将字符串直接输入模型。相反,我们必须先将字符串映射到数字或分类值。分类词汇列提供了一种以 one-hot 矢量表示字符串的好方法。例如:
图 6.将字符串值映射到词汇列。 如您所见,分类词汇列是一种枚举版本的分类标识列。TensorFlow 提供了两个不同的函数来创建分类词汇列: a.tf.feature_column.categorical_column_with_vocabulary_list() b.tf.feature_column.categorical_column_with_vocabulary_file() tf.feature_column.categorical_column_with_vocabulary_list() 函数可以根据一个显式词汇列表将每个字符串映射到一个整数。例如:
前面的函数有一个明显的缺陷;也就是说,当词汇列表较长时,需要进行很多输入工作。对于这些情况,请改为调用 tf.feature_column.categorical_column_with_vocabulary_file(),它让您可以将词汇放在一个单独的文件中。例如:
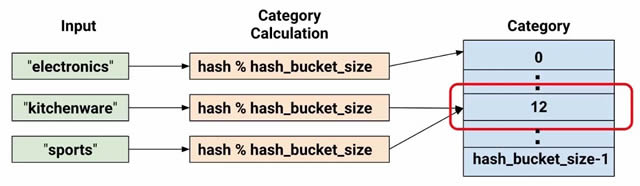
使用哈希存储分区限制类别 到目前为止,我们仅介绍了少量几个类别。例如,我们的 product_class 示例仅有 3 个类别。但是,类别的数量通常可以非常大,以致于无法为每个词汇或整数使用单独的类别,因为这样会消耗大量内存。对于这些情况,我们可以将问题反过来并问问自己,“我愿意为输入使用多少个类别?”事实上,tf.feature_column.categorical_column_with_hash_buckets() 函数让您可以指定类别数量。例如,以下代码显示了此函数如何计算输入的哈希值,然后使用模数运算符将其置于一个 hash_bucket_size 类别中:
此时,您可能会想:“这太疯狂了!”毕竟,我们在将不同的输入值强制放到一组较小的类别中。这意味着,两个很可能完全不相关的输入将被映射到同一个类别,这对神经网络来说也是一样的。图 7 说明了这个难题,显示 kitchenware 和 sports 都分配获得了类别(哈希存储分区)12:
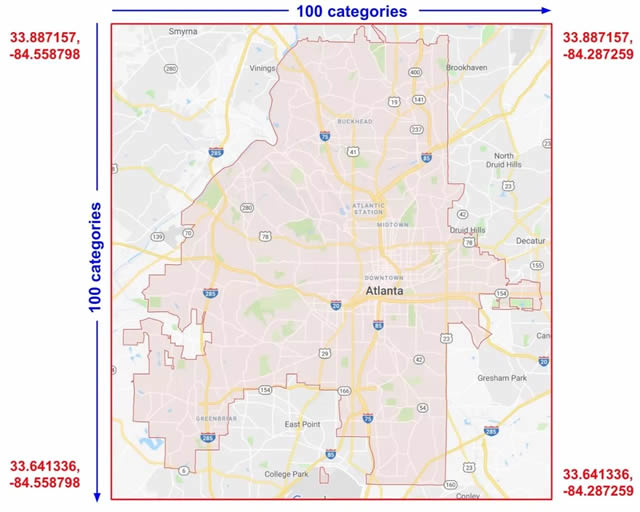
图 7.在哈希存储分区中表示数据 与机器学习中许多有悖常理的现象一样,哈希通常可以在实践中很好地运行。这是因为哈希类别为模型提供了一些分隔。模型可以使用更多特征来进一步将 kitchenware 与 sports 分开。 特征交叉 (Feature crosses) 我们要介绍的最后一个分类列允许我们将多个输入特征组合成一个。组合特征(更广为人知的说法是特征交叉)让模型可以专门针对特征组合表示的任何意义学习单独的权重。 更具体一点,假设我们希望我们的模型计算佐治亚州亚特兰大的房地产价格。这个城市的房地产价格因位置不同而相差很大。以单独的特征表示纬度和经度在确定房地产位置相关性中不是很有用;不过,将纬度和经度组合到一个特征中可以确定位置。假设我们以一个 100x100 大小的矩形剖面网格表示亚特兰大,通过纬度和经度交叉来确定 10,000 个剖面。这个组合让模型可以拾取与各个剖面相关的定价条件,与单独的纬度和经度相比,这样可以提供更强大的信息。
图 8 显示了我们的平面图,其中包含城市四个角落的纬度和经度值:
图 8.亚特兰大地图。将此地图想象成由 10,000 个大小相等的剖面组成 为了解决问题,我们使用了之前介绍过的一些特征列组合,以及 tf.feature_columns.crossed_column() 函数。
您可以从以下信息之一创建特征交叉: a.特征名称;即从 input_fn 返回的 dict 中的名称。 b.任何分类列(参见图 3),除 categorical_column_with_hash_bucket 外。 当特征列 latitude_fc 和 longitude_fc 交叉时,TensorFlow 将创建 10,000 个按以下方式组织的 (latitude_fc, longitude_fc) 组合:
函数 tf.feature_column.crossed_column 将在这些组合上执行哈希计算,然后通过使用 hash_bucket_size 执行模数运算,将结果插入类别中。如之前的讨论一样,执行哈希和模数函数很可能会导致类别冲突;即多个 (纬度, 经度) 特征交叉将出现在同一个哈希存储分区中。不过在实践中,执行特征交叉仍可以为模型的学习能力提供有效值。 有点违反常理的是,在创建特征交叉时,您通常仍需要在模型中包含原始(非交叉)特征。例如,不仅提供 (latitude, longitude) 特征交叉,还需要以单独的特征形式提供 latitude 和 longitude。单独的 latitude 和 longitude 特征将帮助模型分隔包含不同特征交叉的哈希存储分区的内容。 指示器列和嵌入列 (Indicator and Embedding Columns) 指示器列和嵌入列永远不会直接在特征上运行,而是将分类列作为输入。 使用指示器列时,我们将告知 TensorFlow 准确执行我们在分类 product_class 示例中看到的操作。即,指示器列将每个类别作为 one-hot 矢量中的一个元素处理,其中,匹配类别的值为 1,其余为 0:
图 9.在指示器列中表示数据 下面是创建指示器列的方式:
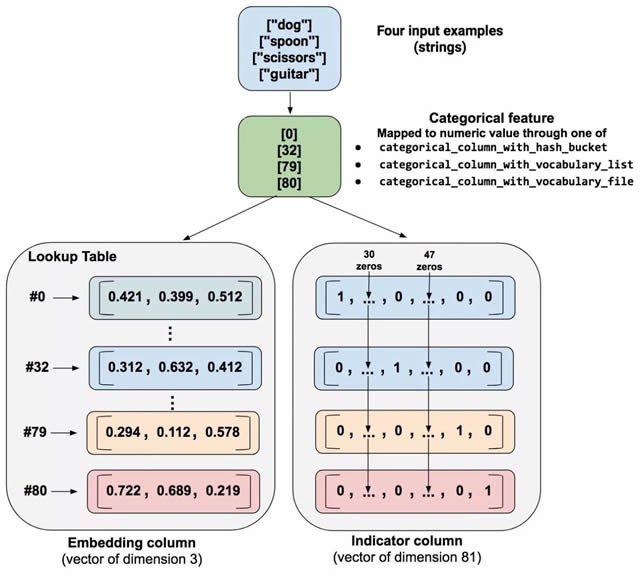
现在,假设我们不只有三个可能的类别,而是有 100 万个。或者有 10 亿个。由于多种原因(技术性过强,我们无法在此介绍),在类别数量增大时,使用指示器列训练神经网络将变得不可行。 我们可以使用嵌入列来克服此限制。与将数据表示为具有许多维度的 one-hot 矢量不同,嵌入列将数据表示为一个更低维度的普通矢量,其中,每个单元格都可以包含任意数字,而不仅仅是 0 或 1。通过为每个单元格允许更丰富的数字组合,与指示器列相比,嵌入列可以包含少得多的单元格数。 我们来看一个比较指示器列和嵌入列的示例。假设我们的输入示例包含一个有限组合中的不同单词,这个组合仅有 81 个单词。再假设数据集在 4 个单独的示例中提供以下输入单词: a."dog" b."spoon" c."scissors" d."guitar" 在这种情况下,图 10 说明了嵌入列或指示器列的处理路径。
图 10.与指示器列相比,嵌入列会将分类数据存储在一个更低维度的矢量中。(我们仅将随机数字置于嵌入矢量中;训练决定实际数字) 在处理一个示例时,一个 categorical_column_with... 函数会将示例字符串映射到数字分类值。例如,一个函数会将 "spoon" 映射到 [32]。(32 来自我们的想象 - 实际值取决于映射函数。)然后,您可以通过以下两种方式之一表示这些数字分类值: a.作为指示器列。函数会将每个数字分类值转换成一个 81 元素矢量(因为我们的组合包含 81 个单词),在分类值 (0, 32, 79, 80) 的索引中放置 1,在其他位置放置 0。 b.作为嵌入列。一个函数使用数字分类值 (0, 32, 79, 80) 作为查找表的索引。查找表中的每个显示位置都包含一个 3 元素矢量。 嵌入矢量中的值是怎样神奇地获得分配的?实际上,分配发生在训练期间。即,模型将学习最佳方式来将您的输入数字分类值映射到嵌入矢量值,求解您的问题。嵌入列可以提升您的模型的能力,因为嵌入矢量可以从训练数据中学习类别之间的新关系。 我们示例中矢量的大小为什么是 3?以下“公式”提供了与嵌入维度数量有关的一般经验法则: embedding_dimensions = number_of_categories**0.25 即,嵌入矢量维度应等于类别数量的四次方根。由于此示例中的词汇大小为 81,建议的维度数量为 3: 3 = 81**0.25 请注意,这只是一个一般准则;您可以随意设置嵌入维度的数量。 调用 tf.feature_column.embedding_column 来创建一个 embedding_column。嵌入矢量的维度取决于上面介绍的手头问题,但常用值可以从最低的 3 开始,一直到 300 或更大: categorical_column = ... # Create any categorical column shown in Figure 3.
嵌入是机器学习领域的一个大主题。此信息旨在帮助您开始将它们用作特征列。请参阅此文的结尾了解更多信息。 将特征列传递到估算器(estimators) 还在看吗?我希望大家还在看,因为特征列的基础知识马上就要介绍完了。 正如我们在图 1 中看到的一样,特征列可以将您的输入数据(通过从 input_fn 返回的特征字典进行说明)映射到要提供给模型的值。以列表形式将特征列指定到估算器的 feature_columns 参数。请注意,feature_columns 参数因估算器的不同而有所差异: a.视频广告怎么制作LinearClassifier 和 LinearRegressor: 接受所有类型的特征列。 b.DNNClassifier 和 DNNRegressor: 仅接受密集列,请参见图 3。如之前所述,其他列类型必须包装在 indicator_column 或 embedding_column 中。 c.DNNLinearCombinedClassifier 和 DNNLinearCombinedRegressor: linear_feature_columns 参数可以接受任意列类型,像上面的 LinearClassifier 和 LinearRegressor 一样。 不过,dnn_feature_columns 参数被限制为密集列,像上面的 DNNClassifier 和 DNNRegressor 一样。 上述规则的原因超出了这篇介绍文章的范围,不过,我们会在未来的文章中确保对此进行介绍。 总结 使用特征列可以将您的输入数据映射到您向模型提供的表示。不过使用这篇文章介绍的其他函数,您可以轻松创建其他特征列。 
|














上一篇:Facebook如何选择合适的成效衡量解决方案
下一篇:网易态度营销大赏
版权声明:以上主题为“Google:TensorFlow怎样表示非数值特征类型"的内容可能是本站网友自行发布,或者来至于网络。如有侵权欢迎联系我们客服QQ处理,谢谢。
- 搜索营销推广之前要做的几步准备工作
 搜索推广是用关键词来锁定不同人群,通过相关搜索结...
搜索推广是用关键词来锁定不同人群,通过相关搜索结... - 搜索引擎作为网民的重要入口的方式之一
互联网圈中有一句话,谁把握了入口,谁就成功了一半...
- Google Analytics 5种方法解读网站分析数据
数据是进行网站分析的基础,Google Analytics为 一个网站...
- 搜索营销效果评估的四量 消费量 流量 对
对于竞价推广来说,转化率一般由以下4个量决定的,分...
- 企业品牌要具备“社交化”数字营销思维
如今所有的品牌在都面临着这样的困惑,消费者的变化...
- 搜索引擎营销的概念、范围、目的和意义
搜索引擎营销带来流量只是一方面,更重要的方面是带...
- 内贸企业如何搭建自有网络营销体系
在国内做贸易的企业通常分为两大类:一种是生产型企...
- Google趋势查询工具
 通过 Google 趋势,您可以比较全世界对您所喜爱主题的...
通过 Google 趋势,您可以比较全世界对您所喜爱主题的... - 内贸企业网络营销的六大误区与对策
随着互联网的风生水起,网络营销以其快捷、低成本、...
- PR值查询工具
 Google PageRank (网页级别) 是 Google 搜索引擎用于评测一个...
Google PageRank (网页级别) 是 Google 搜索引擎用于评测一个...

打开微信扫码或长按识别二维码
小提示:您应该对本页介绍的“Google:TensorFlow怎样表示非数值特征类型”相关内容感兴趣,若您有相关需求欢迎拨打我们的服务热线或留言咨询,我们尽快与您联系沟通Google:TensorFlow怎样表示非数值特征类型的相关事宜。
关键词:Google